
M1은 RISC-V 마이크로 프로세서에 도움이 되는 패러다임 전환의 시작이지만 그 과정은 쉽게 생각할 수 있는 방식은 아닙니다.

애플의 M1 칩이 대단한 것이 분명합니다.
그리고 나머지 업계에 미치는 영향은 점차 명확 해지고 있습니다.
이 이야기에서는 대부분의 독자들에게 분명하지 않을 수 있는 RISC-V 마이크로 프로세서와의 연결에 대해 이야기하고 싶습니다.
먼저 몇 가지 배경 지식을 드리겠습니다. 지난 블로그를 먼저 보십시요.
도대체 애플 M1 칩은 왜 빠를까?
YouTube에는 작년에 산 40GB RAM 최대 4,000 달러 이상의 고가 iMac이 700 달러 정도의 새로운 M1 Mac Mini에 성능상으로 뒤지는 영상에 많이 올라왔었습니다. 실전 테스트에서도 벤치마크상의 숫자와 비슷
cpro95.tistory.com
이전 이야기에서 M1 성능을 이끄는 두 가지 요소에 대해 이야기했습니다.
하나는 엄청난 수의 디코더와 OoOE (Out-of-Order Execution)의 사용이었습니다.
당신에게 기술적으로 외계어처럼 들리더라도 걱정하지 마십시오.
이 이야기는 다른 부분인 이질적 컴퓨팅에 관한 것입니다.
Apple은 특수 하드웨어 장치를 추가하는 전략을 적극적으로 추구하고 있습니다.
이 글에서는 보조 프로세서라고 합니다.
- 데이터 병렬 처리가 많은 그래픽 및 기타 여러 작업을 위한 GPU (Graphical Processing Unit) (동시에 여러 요소에서 동일한 작업 수행).
- 신경 엔진. 기계 학습을 수행하기위한 특수 하드웨어.
- 이미지 처리를위한 디지털 신호 처리 하드웨어.
- 하드웨어의 비디오 인코딩.
더 많은 범용 프로세서를 솔루션에 추가하는 대신 Apple은 솔루션에 더 많은 보조 프로세서를 추가하기 시작했습니다.
가속기라는 용어를 사용할 수도 있습니다.
이것은 완전히 새로운 트렌드는 아닙니다.
1985 년에 출시 된 오래된 Amiga 1000에는 오디오 및 그래픽 속도를 높이기 위한 보조 프로세서가 있었습니다.
최신 GPU는 본질적으로 코 프로세서(coprocessor)입니다.
Google의 Tensor Processing Unit은 머신 러닝에 사용되는 코 프로세서(coprocessor)의 한 형태입니다.

코 프로세서(Coprocessor)란 무엇입니까?
CPU와 달리 보조 프로세서는 혼자 살 수 없습니다.
보조 프로세서를 집어 넣는 것만으로는 컴퓨터를 만들 수 없습니다.
코 프로세서는(coprocessor) 특정 작업을 정말 잘 수행하는 특수 목적 프로세서로서의 보조 프로세서입니다.
코 프로세서는(coprocessor)의 초기 사례 중 하나는 Intel 8087 부동 소수점 장치 (FPU)였습니다.
겸손한 인텔 8086 마이크로 프로세서는 정수 산술을 수행 할 수 있지만 부동 소수점 산술은 수행 할 수 없습니다.
차이점은 무엇일까요?

정수는 43, -5, 92, 4와 같은 숫자입니다.
이들은 컴퓨터에서 작업하기가 매우 쉽습니다.
간단한 칩으로 정수를 추가하는 솔루션을 함께 연결할 수 있습니다.
문제는 소수를 다룰 때 시작됩니다.
4.25, 84.7 또는 3.1415와 같은 숫자를 더하거나 곱하고 싶다고 가정합니다.
위 숫자는 부동 소수점 숫자의 예입니다.
포인트 이후의 자릿수가 고정되면 고정 소수점 숫자라고 부릅니다.
돈은 종종 이런 식으로 취급됩니다.
일반적으로 포인트 뒤에 소수점 두 자리가 있습니다.
그러나 정수로 부동 소수점 산술을 에뮬레이션 할 수 있지만 속도가 느립니다.
이것은 초기 마이크로 프로세서가 정수를 곱할 수 없었던 것과 비슷합니다.
더하기와 빼기만 할 수 있습니다.
그러나 여전히 곱셈을 수행 할 수 있습니다.
단순히 덧셈을 여러번 에뮬레이트해야 됩니다. 예를 들어 3 × 4는 단순히 4 + 4 + 4입니다.
아래 코드 예제를 이해하는 것은 중요하지 않지만 CPU에서 더하기, 빼기 및 분기 (코드에서 점프)를 사용해야 만 곱셈을 수행 할 수 있는 방법을 이해하는 데 도움이 될 수 있습니다.
loadi r3, 0 ; Load 0 into register r3
multiply:
add r3, r1 ; r3 ← r3 + r1
dec r2 ; r2 ← r2 - 1
bgt r2, multiply ; goto multiply if r2 > 0
요컨대, 더 간단한 연산을 반복하여 항상 더 복잡한 수학 연산을 수행 할 수 있습니다.
모든 코 프로세서(coprocessor)가 하는 일은 이것과 비슷합니다.
CPU가 보조 프로세서와 동일한 작업을 수행하는 방법은 항상 있습니다.
그러나 이것은 일반적으로 여러 간단한 작업을 반복해야합니다.
초기에 GPU를 얻은 이유는 수백만 개의 폴리곤 또는 픽셀에서 동일한 계산을 반복하는 것이 CPU에 실제로 시간이 많이 걸리기 때문입니다.
코 프로세서(coprocessor)에서 데이터를 전송하는 방법
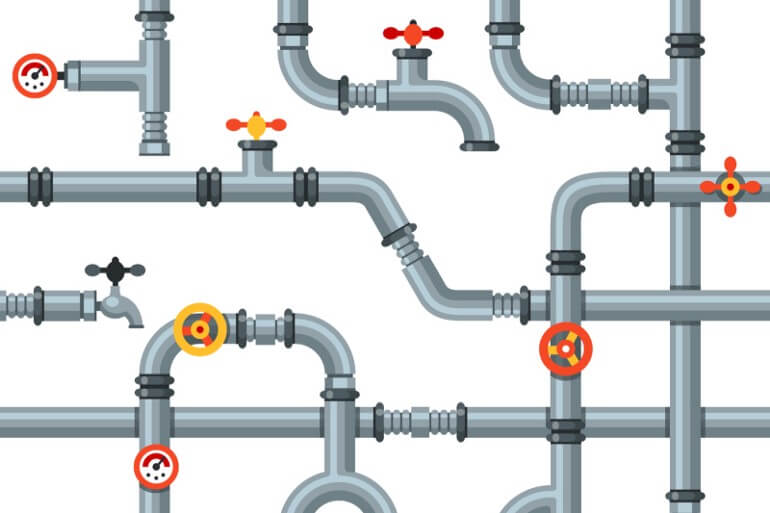
코 프로세서(coprocessor)가 마이크로 프로세서(CPU) 또는 범용 프로세서와 함께 작동하는 방식을 더 잘 이해하기 위해 아래 다이어그램을 살펴 보겠습니다.

녹색 및 하늘색 버스를 파이프라고 생각할 수 있습니다.
숫자는이 파이프를 통해 전달되어 CPU의 다른 기능 단위 (회색 상자로 표시됨)에 도달합니다.
이 상자의 입력 및 출력은이 파이프에 연결됩니다.
각 상자의 입력과 출력을 밸브가있는 것으로 생각할 수 있습니다.
빨간색 제어 라인은 이러한 밸브를 열고 닫는 데 사용됩니다.
따라서 빨간색 선을 담당하는 디코더는 두 개의 회색 상자에있는 밸브를 열어 숫자가 서로 흐르도록 할 수 있습니다.
이를 통해 메모리에서 데이터를 가져 오는 방법을 설명 할 수 있습니다.
숫자에 대한 연산을 수행하려면 레지스터에 숫자가 필요합니다.
디코더는 제어 라인을 사용하여 회색 메모리 상자와 레지스터 상자 사이의 밸브를 엽니다.
이것이 구체적으로 일어나는 방법입니다.
- 디코더는 LSU (Load Store Unit)의 밸브를 열어 메모리 주소가 녹색 주소 버스로 흘러 나오게합니다.
- 메모리 상자에 다른 밸브가 열려 주소를받을 수 있습니다. 초록색 파이프 (주소 버스)로 배달됩니다. 다른 모든 밸브는 닫혀 있습니다. 입 / 출력이 주소를받을 수 없습니다.
- 주어진 주소를 가진 메모리 셀이 선택됩니다. Decoder가 데이터 버스에 대한 밸브를 열었 기 때문에 그 내용은 파란색 데이터 버스로 흐릅니다.
- 메모리 셀의 데이터는 어디로든 흐를 수 있지만 디코더는 레지스터에 대한 입력 밸브 만 열었습니다.
마우스, 키보드, 화면, GPU, FPU, 신경 엔진 및 기타 보조 프로세서와 같은 것은 입력 / 출력 상자와 동일합니다.
메모리 위치와 마찬가지로 액세스합니다.
하드 드라이브, 마우스, 키보드, 네트워크 카드, GPU, DMA (직접 메모리 액세스) 및 보조 프로세서에는 모두 메모리 주소가 매핑되어 있습니다.
하드웨어는 주소를 지정하여 메모리 위치와 마찬가지로 액세스됩니다.
그게 정확히 무슨 뜻일까요?
주소를 좀 만들어 보겠습니다.
프로세서가 메모리 주소 84에서 읽기를 시도하면 컴퓨터 마우스의 x 좌표를 의미 할 수 있습니다.
85는 y 좌표를 의미합니다.
따라서 마우스 좌표를 얻으려면 어셈블리 코드에서 다음과 같이해야합니다.
load r1, 84 ; get x-coordinate
loar r2, 85 ; get y-coordinate
DMA 컨트롤러의 경우 특별한 의미로 110, 111 및 113 주소가 있을 수 있습니다.
다음은 이를 사용하여 DMA 컨트롤러와 상호 작용하는 비현실적인 조립 코드 프로그램입니다.
loadi r1, 1024; 레지스터 r을 소스 주소로 설정
loadi r2, 50; 복사 할 바이트
loadi r3, 2048; 목적지 주소
저장 r1, 110; DMA 컨트롤러 시작 주소 알려주기
저장 r2, 111; DMA에 50 바이트를 복사하도록 지시
저장 r3, 113; 50 바이트를 복사 할 위치를 DMA에 알립니다.모든 것이 이러한 방식으로 작동합니다.
특수 메모리 주소를 읽고 씁니다.
물론 일반 소프트웨어 개발자는 이것을 보지 못합니다.
이 작업은 장치 드라이버에 의해 수행됩니다.
사용하는 프로그램은 이것이 보이지 않는 가상 메모리 주소 만 볼 수 있습니다.
그러나 드라이버는 이러한 주소를 가상 메모리 주소에 매핑합니다.

나는 가상 메모리에 대해 너무 많이 말하지 않을 것입니다.
본질적으로 우리는 실제 주소를 얻었습니다.
녹색 버스의 주소는 가상 주소에서 실제 물리적 주소로 변환됩니다.
DOS에서 C / C ++로 프로그래밍을 시작했을 때 그런 것이 없었습니다.
비디오 메모리의 메모리 주소를 직접 가리 키도록 C 포인터를 설정하고 사진을 변경하기 위해 바로 쓰기를 시작할 수 있습니다.
char * video_buffer = 0xB8000; // CGA 비디오 버퍼에 대한 포인터 설정
video_buffer [3] = 42; // 네 번째 픽셀의 색상 변경
...
...
코 프로세서(coprocessor)는 이와 같은 방식으로 작동합니다.
Neural Engine, GPU, Secure Enclave 등에는 통신하는 주소가 있습니다.
이것들과 DMA 컨트롤러와 같은 것에 대해 알아야 할 중요한 것은 비동기 적으로 작동 할 수 있다는 것입니다.
즉, CPU는 Neural Engine 또는 GPU에 대한 전체 명령을 정렬하여 메모리의 버퍼에 기록 할 수 있습니다.
그런 다음 IO 주소와 대화하여 이러한 명령의 위치를 Neural Engine 또는 GPU 코 프로세서에 알립니다.
CPU가 거기에 앉아 코 프로세서가 모든 명령과 데이터를 처리 할 때까지 대기하는 것을 원하지 않습니다.
DMA에서도 그렇게하고 싶지 않습니다.
이것이 일반적으로 일종의 인터럽트를 제공 할 수있는 이유입니다.
인터럽트는 어떻게 작동할까요?
그래픽 카드든 네트워크 카드든 PC에 붙인 다양한 카드에는 인터럽트 라인이 할당됩니다.
CPU로 곧바로 연결되는 선과 같습니다.
이 라인이 활성화되면 CPU는 인터럽트를 처리하기 위해 보유하고 있는 모든 것을 삭제합니다.
또는 더 구체적으로 현재 위치와 레지스터 값을 메모리에 저장하므로 나중에 수행하던 작업으로 돌아갈 수 있습니다.
다음으로 소위 인터럽트 테이블에서 수행 할 작업을 찾습니다.
테이블에는 인터럽트가 트리거 될 때 실행하려는 프로그램의 주소가 있습니다.
프로그래머로서 당신은 이런 것들을 보지 못합니다.
당신에게는 특정 이벤트에 등록하는 콜백 함수처럼 보일 것입니다.
운전자는 일반적으로 낮은 수준에서 이를 처리합니다.
왜 이 모든 엉뚱한 세부 사항을 말하고 있을까요? 코 프로세서(coprocessor)를 사용할 때 무슨 일이 일어나고 있는지에 대한 직관을 개발하는 데 도움이 되기 때문입니다.
그렇지 않으면 코 프로세서(coprocessor)와의 통신에 실제로 수반되는 것이 무엇인지 명확하지 않습니다.
인터럽트를 사용하면 많은 일이 병렬로 발생할 수 있습니다.
CPU가 컴퓨터 마우스에 의해 중단되는 동안 응용 프로그램은 네트워크 카드에서 이미지를 가져올 수 있습니다.
마우스가 이동되었으며 새 좌표가 필요합니다.
CPU는 이것을 읽고 GPU로 보낼 수 있으므로 새 위치에 마우스 커서를 다시 그릴 수 있습니다.
GPU가 마우스 커서를 그릴 때 CPU는 네트워크에서 검색된 이미지 처리를 시작할 수 있습니다.
마찬가지로 이러한 인터럽트를 사용하여 복잡한 기계 학습 작업을 M1 Neural Engine에 보내 WebCam에서 얼굴을 식별 할 수 있습니다.
Neural Engine이 CPU가 수행하는 다른 모든 작업과 병렬로 이미지 데이터를 씹기 때문에 나머지 컴퓨터는 동시에 반응합니다.

The Rise of RISC-V
2010년 UC Berkley에서 Parallel Computing Laboratory는 코 프로세서(coprocessor)를 더 많이 사용하는 방향으로 발전했습니다.
무어의 법칙의 끝이 범용 CPU 코어에서 더 많은 성능을 더 이상 쉽게 끌어낼 수 없음을 의미하는 것을 보았습니다.
특수 하드웨어가 필요했습니다. 바로 코 프로세서(coprocessor)입니다.
그 이유를 잠시 생각해 보겠습니다.
우리는 클럭 주파수를 쉽게 증가시킬 수 없다는 것을 알고 있습니다.
우리는 3 ~ 5GHz에 가깝습니다.
더 높아지면 와트 소비와 열 발생이 천정부지로 올라갑니다.
그러나 우리는 더 많은 트랜지스터를 추가 할 수 있습니다.
우리는 트랜지스터를 더 빠르게 작동시킬 수 없습니다.
따라서 더 많은 작업을 병렬로 수행해야합니다.
이를 수행하는 한 가지 방법은 범용 코어를 많이 추가하는 것입니다.
이전에 논의했듯이 많은 디코더를 추가하고 OoOE (Out-of-Order Execution)를 수행 할 수 있습니다.
트랜지스터 예산 : CPU 코어 또는 코 프로세서?
위 질문에 고민하다 보면 결국 Ampere Altra Max ARM 프로세서와 같은 128 개의 일반 코어를 볼 수 있습니다.
하지만 이것이 정말로 우리 실리콘의 최선의 사용일까요?
훌륭한 클라우드의 서버를 위해 다양한 클라이언트 요청으로 128개의 코어를 모두 바쁘게 유지할 수 있습니다.
그러나 데스크톱 시스템은 일반적인 데스크톱 워크로드에서 8코어 이상을 효과적으로 사용하지 못할 수 있습니다.
따라서 32 코어라고하면 대부분의 시간 동안 유휴 상태에있는 많은 코어에서 실리콘을 낭비하는 것입니다.
더 많은 CPU 코어에 모든 실리콘을 소비하는 대신 보조 프로세서를 더 추가 할 수 있습니까?
이렇게 생각해보십시오.
트랜지스터 예산이 있습니다.
초기에는 트랜지스터 20,000 개의 예산이 있었고 15,000 개의 트랜지스터로 CPU를 만들 수 있다고 생각했을 것입니다.
그것은 80 년대 초반 현실에 가깝습니다.
이제 이 CPU는 약 100 개의 다른 작업을 수행 할 수 있습니다.
이러한 작업 중 하나에 특수 코 프로세서(coprocessor)를 만드는 데 1000 개의 트랜지스터가 필요하다고 가정 해 보겠습니다.
모든 작업에 대해 보조 프로세서를 만들면 100,000 개의 트랜지스터를 얻을 수 있습니다.
그것은 당신의 예산을 초과 할 것입니다.
트랜지스터 풍족도 변경 전략
따라서 초기 설계에서는 범용 컴퓨팅에 집중해야했습니다.
그러나 오늘날 우리는 너무 많은 트랜지스터로 칩을 채울 수 있으므로 어떻게 해야 할지 거의 알지 못합니다.
따라서 코 프로세서(coprocessor)를 설계하는 것이 큰 일이 되었습니다.
모든 종류의 새로운 보조 프로세서를 만드는 데 많은 연구가 진행됩니다.
그러나 이것들은 베이비가 필요한 꽤 멍청한 가속기를 포함하는 경향이 있습니다.
CPU와 달리 그들은 해야 할 모든 단계를 알려주는 명령을 읽을 수 없습니다.
그들은 일반적으로 메모리에 액세스하고 무엇이든 정리하는 방법을 모릅니다.
따라서 이에 대한 일반적인 해결책은 일종의 컨트롤러로 간단한 CPU를 사용하는 것입니다.
따라서 전체 코 프로세서(coprocessor)는 간단한 CPU에 의해 제어되는 일부 특수 가속기 회로이며, 이 회로는 가속기를 작업을 수행하도록 구성합니다.
일반적으로 이것은 고도로 전문화되어 있습니다.
예를 들어, Neural Engine 또는 Tensor Processing Unit과 같은 것은 행렬 (숫자의 행과 열)을 보유 할 수있는 매우 큰 레지스터를 처리합니다.
RISC-V는 가속기를 제어하도록 맞춤 제작되었습니다.
이것이 바로 RISC-V가 설계된 목적입니다.
그것은 모든 일반적인 CPU 작업을 수행 할 수 있도록 약 40-50 개의 명령어로 구성된 최소 명령어 세트를 가지고 있습니다.
많이 들릴지 모르지만 x86 CPU에는 1500 개 이상의 명령이 있습니다.
큰 고정 명령 세트 대신 RISC-V는 확장 개념을 중심으로 설계되었습니다.
모든 보조 프로세서는 다릅니다.
따라서 코어 명령어 세트를 구현하는 작업을 관리하기위한 RISC-V 프로세서와 코 프로세서가 수행해야하는 작업에 맞게 만들어진 확장 명령어 세트가 포함됩니다.
이제 당신은 내가 얻고 있는 것의 윤곽을보기 시작할 것입니다.
Apple의 M1은 업계 전체를 이 보조 프로세서가 지배하는 미래로 향하게 할 것입니다.
그리고 이러한 보조 프로세서를 만들기 위해 RISC-V는 퍼즐의 중요한 부분이 될 것입니다.
그런데 왜 코 프로세서(coprocessor)를 만드는 모든 사람이 자신의 명령어 세트를 만들 수는 없나요?
잘은 모르겠지만 애플은 자신만의 명령어 세트를 만든거 같기도 합니다.
코 프로세서(coprocessor)용 RISC-V를 고수하면 어떤 이점이 있습니까?
칩을 만드는 것은 복잡하고 비용이 많이 드는 일이 되었습니다.
칩 검증을 위한 도구 구축, 테스트 프로그램, 진단 및 기타 여러 가지를 실행하려면 많은 노력이 필요합니다.
이것은 오늘날 ARM과 함께하는 가치의 일부입니다.
설계를 확인하고 테스트하는 데 도움이되는 대규모 도구 에코 시스템이 있습니다.
따라서 사용자 지정 독점 명령 집합을 사용하는 것은 좋은 생각이 아닙니다.
그러나 RISC-V에는 여러 회사에서 도구를 만들 수 있는 표준이 있습니다.
갑자기 생태계가 생겨 여러 회사가 부담을 공유 할 수 있습니다.
하지만 이미 있는 ARM을 사용하지 않는 이유는 무엇일까요?
ARM은 범용 CPU로 만들어졌습니다.
큰 고정 명령 세트가 있습니다.
고객의 압력과 RISC-V 경쟁에 힘입어 ARM은 2019 년 확장을 위한 명령어 세트를 열었습니다.
여전히 문제는 처음부터 이를 위해 만들어지지 않았다는 것입니다.
전체 ARM 툴체인은 전체 대형 ARM 명령어 세트를 구현했다고 가정합니다.
Mac이나 iPhone의 메인 CPU에서는 괜찮습니다.
그러나 보조 프로세서의 경우 이 큰 명령 집합을 원하거나 필요로하지 않습니다.
확장 기능이 있는 최소 고정 기본 명령어 세트라는 아이디어를 기반으로 구축 된 도구의 에코 시스템을 원합니다.
RISC-V 기반 컨트롤러를 사용하는 Nvidia
그게 왜 그렇게 유익할까요?
Nvidia의 RISC-V 사용은 몇 가지 통찰력을 제공합니다.
대형 GPU에서는 컨트롤러로 사용할 일종의 범용 CPU가 필요합니다.
그러나 이를 위해 따로 보관할 수있는 실리콘의 양과 생산할 수있는 열의 양은 최소화됩니다.
많은 것들이 공간(space)을 놓고 경쟁하고 있음을 명심하십시오.
RISC-V의 작고 간단한 명령어 세트를 통해 ARM보다 훨씬 적은 실리콘으로 RISC-V 코어를 구현할 수 있습니다.
RISC-V는 작고 간단한 명령어 세트를 가지고 있기 때문에 ARM을 포함한 모든 경쟁 제품을 능가합니다.
Nvidia는 다른 누구보다 RISC-V를 선택하면 더 작은 칩을 만들 수 있음을 발견했습니다.
또한 와트 사용량을 최소로 줄였습니다.
따라서 확장 메커니즘을 사용하면 수행해야 하는 작업에 중요한 지침만 추가하도록 제한 할 수 있습니다.
GPU 용 컨트롤러에는 암호화 코 프로세서(coprocessor)의 컨트롤러가 아닌 다른 확장이 필요할 수 있습니다.
RISC-V 기계 학습 가속기 (ET-SOC-1)
Esperanto Technologies는 RISC-V에서 가치를 발견한 또 다른 회사입니다.
그들은 M1 SoC보다 약간 큰 ET-SOC-1이라는 SoC를 만들고 있습니다.
M1의 160억개에 비해 238억 개의 트랜지스터가 있습니다.

범용 파이어 스톰 코어 4 개 대신 ET-Maxion이라고하는 4 개의 RISC-V 코어입니다.
이들은 Linux 운영 체제를 실행하는 것과 같은 범용 작업을 수행하는 데 적합합니다.
그러나이 외에도 ET-Minion이라는 1000 개 이상의 특수 보조 프로세서가 있습니다.
이들은 RISC-V 벡터 확장을 구현하는 RISC-V 기반 코 프로세서입니다.
그 의미는 무엇일까요?
이 명령어는 특히 현대 기계 학습에 관한 큰 벡터와 행렬을 처리하는 데 적합합니다.
불신의 코어 수를 보고있을 수 있습니다.
ET-SOC-1은 M1보다 더 많은 코어를 어떻게 가질 수 있을까요?
Firestorm 코어는 쉽게 병렬화 할 수 없는 일반적인 데스크톱 워크로드를 처리하기위한 것입니다.
따라서 코드를 병렬로 실행하기 위해서는 많은 트릭이 필요합니다.
그것은 많은 실리콘을 먹습니다.
대조적으로 ET-Minion 코어는 병렬화가 사소한 문제를 처리하므로 이러한 코어는 정말 간단하여 필요한 실리콘의 양을 줄일 수 있습니다.
ET-SOC-1의 핵심 사항은 고도로 전문화 된 코 프로세서(coprocessor)의 생산자가 RISC-V를 기반으로 한 코 프로세서를 구축하는 데있어 가치를 보고 있다는 것입니다.
ET-Maxion과 ET-Minion 코어는 모두 Esperanto Technologies로부터 라이센스를 받을 수 있습니다.
이는 이론상 Apple (또는 다른 사람)이 ET-Minion 코어에 라이선스를 부여하고 M1에 많은 코어를 배치하여 우수한 머신 러닝 성능을 얻을 수 있음을 의미합니다.
ARM은 새로운 x86이 될 것입니다.
아이러니하게도 우리는 Mac과 PC가 ARM 프로세서로 구동되는 미래를 볼 수 있습니다.
그러나 주변의 모든 맞춤형 하드웨어가있는 곳에서는 모든 코 프로세서(coprocessor)가 RISC-V에 의해 지배 될 것입니다.
코 프로세서(coprocessor)가 대중화됨에 따라 SoC (System-on-a-Chip)에서 더 많은 실리콘이 ARM보다 RISC-V를 실행할 수 있습니다.
RISC-V 코 프로세서(coprocessor) 군대를 지휘하는 ARM
범용 ARM 프로세서는 그래픽, 암호화, 비디오 인코딩, 기계 학습, 신호 처리에서 네트워크 패키지 처리에 이르기까지 가능한 모든 작업을 가속화하는 RISC-V 기반 코 프로세서(coprocessor) 군대와 함께 중심에 있을 것입니다.
UC Berkeley의 David Patterson 교수와 그의 팀은 이러한 미래가 다가오는 것을 보았습니다.
이것이 RISC-V가이 새로운 세상에 잘 맞도록 조정 된 이유입니다.
우리는 모든 종류의 특수 하드웨어 및 마이크로 컨트롤러에서 RISC-V에 대한 엄청난 관심과 소문을보고 있으며 오늘날 ARM이 지배하는 많은 영역이 RISC-V가 될 것이라고 생각합니다.

Raspberry Pi와 같은 것을 상상해보십시오.
ARM 방식으로 실행합니다.
그러나 미래의 RISC-V 변종은 다양한 요구에 맞는 다양한 변종을 제공 할 수 있습니다.
머신 러닝 마이크로 컨트롤러가 있을 수 있습니다.
다른 하나는 이미지 처리 지향적 일 수 있습니다.
세 번째는 암호화를 위한 것일 수 있습니다.
기본적으로 자신 만의 작은 맛을 가진 작은 마이크로 컨트롤러를 선택할 수 있습니다.
Linux를 실행하고 성능 프로필이 다를 수 있다는 점을 제외하고는 모두 동일한 작업을 수행 할 수 있습니다.
특수 기계 학습 지침이 있는 RISC-V 마이크로 컨트롤러는 비디오 인코딩 지침이있는 RISC-V 마이크로 컨트롤러보다 빠르게 신경망을 훈련시킵니다.
Nvidia는 아래에 표시된 Jetson Nano로 이미 그 길을 걸어 왔습니다.
기계 학습을위한 특수 하드웨어를 갖춘 Raspberry Pi 크기의 마이크로 컨트롤러이므로 물체 감지, 음성 인식 및 기타 기계 학습 작업을 수행 할 수 있습니다.

RISC-V를 메인 CPU로 사용?
많은 사람들이 묻습니다.
ARM을 RISC-V로 완전히 교체하지 않는 이유는 무엇입니까?
다른 사람들은 RISC-V가 ARM과 x86이 제공하는 고성능을 제공 할 수없는 "고통스럽고 간단한" 명령어 세트를 가지고 있기 때문에 이것이 작동하지 않을 것이라고 주장합니다.
예, RISC-V를 메인 프로세서로 사용할 수 있습니다.
아니요, 성능이 우리를 방해하지 않습니다.
ARM과 마찬가지로 고성능 RISC-V 칩을 만들 사람이 필요합니다.
실제로 이미 완료되었을 수 있습니다.
새로운 RISC-V CPU는 와트 당 기록적인 성능을 자랑합니다.
복잡한 명령어가 더 높은 성능을 제공한다는 것은 일반적인 오해였습니다.
RISC 워크 스테이션은 90년대에 성능 벤치 마크에서 x86 컴퓨터를 파괴하면서 이를 반증했습니다.
사실, RISC-V는 고성능을 얻기위한 많은 영리한 트릭을 가지고 있습니다.
요컨대 메인 CPU가 RISC-V 프로세서가 될 수 없는 이유는 없지만 이 역시 추진력의 문제입니다.
MacOS와 Windows는 이미 ARM에서 실행되고 있습니다.
적어도 단기적으로는 마이크로 소프트나 애플이 또 다른 하드웨어 전환을 위해 노력할 것이라는 것은 의심스러워 보인다.
'사용기' 카테고리의 다른 글
| 아이폰 HEIC 사진을 JPG 사진으로 변환하기 (0) | 2021.05.05 |
|---|---|
| 애플 M1 칩 X86 에뮬 성능은 왜 빠른가? (0) | 2021.05.02 |
| NodeJS, npm install 중 permission denied 에러 해결하기 (0) | 2021.02.16 |
| 맥 gem install cocoapods 인스톨 에러 (0) | 2021.02.10 |
| 입주를 앞두고 가구를 준비하다 (마석 까소엔) (0) | 2020.12.28 |