
5. 변수의 형식과 변환
C++에서의 계산은 동일한 형식을 가지는 변수 사이에서만 이루어진다. 여러분이 다른 형식을 가지는 변수 또는 상수를 포함하는 표현을 작성할 때 컴파일러는 수행되어야 할 각각의 작업에 대해서 피연산자 중의 하나의 형식을 다른 것과 일치시키기 위해서 그 형식을 변환시키는 작업을 해야만 한다. 이러한 변환 작업을 변환(casting)이라고 한다. 예를 들어, 여러분이 double 형식의 값을 정수에 더하려고 한다면 먼저 그 정수 값이 double로 변환된다. 그 뒤에 덧셈 작업이 수행된다. 물론, 변환될 값을 포함하고 있는 변수 그 자체는 바뀌지 않는다. 컴파일러는 변환된 값을 임시 메모리의 장소에 저장한다. 그 메모리 장소는 그 계산 작업이 끝나면 폐기된다.
모든 연산에서 변환되어야 하는 피연산자를 선택하는 규칙이 있다. 계산되어야 할 모든 표현은 두 개의 피연산자 사이에서 수행되어야 할 일련의 작업으로 나뉜다. 예를 들어, 2*3-4+5라는 표현은 2*3은 6, 6-4는 2, 마지막으로 2+5는 7과 같이 일련의 작업으로 나뉜다. 그러므로 피연산자를 변환시키는 규칙은 두 개의 피연산자 중에서 어떤 것을 변환시킬 것인가에 대하여 결정할 때만 정의되어야 한다. 서로 다른 형식을 가지고 있는 모든 피연산자들에 대해서 다음과 같은 규칙들이 그것이 나타나 있는 순서대로 검사된다. 그중에서 하나의 규칙이 적용되면 그 규칙이 사용된다.
피연산자를 변환하는 규칙
1. 만약 피연산자 중의 어느 하나라 long double 형식을 가진다면 다른 피연산자도 long double로 변환된다.
2. 만약 피연산자 중의 어느 하나가 double 형식을 가진다면 다른 피연산자도 double로 변환된다.
3. 만약 피연산자 중의 어느 하나가 float 형식을 가진다면 다른 피연산자도 float로 변환된다.
4. char, singedchar, unsigned char, short 또는 unsigned short 형식을 가지는 피연산자는 int 형식으로 변환된다.
5. 목록 형식은 다음과 같은 순서로 나타나 있는 형식 중에서 열거자가 가지는 범위를 포함할 수 있는 첫 번째의 형식으로 변환된다(int, unsigned int, long, unsigned long).
6. 만약 피연산자 중의 어느 하나가 unsigned long 형식을 가진다면 다른 피연산자도 unsigned long으로 변환된다.
7. 만약 하나의 피연산자가 long 형식을 가지고, 다른 피연산자가 unsigned int를 가진다면 그 두 피연산자는 unsigned long 형식으로 변환된다.
8. 만약 피연산자 중의 어느 하나가 long 형식을 가진다면 다른 피연산자도 long으로 변환된다.
위의 규칙은 상당히 복잡한 것처럼 보인다. 그러나 기본적인 원칙은 항상 다른 피연산자와 비교해서 적은 범위의 값을 가지는 형식을 좀 더 넓은 범위의 값을 가지는 형식으로 변환하는 것이다. 결과를 최대한도로 수용할 수 있도록 한다. 이것이 어떻게 작동하는지 살표보기 위해서 가상의 표현에 대해서 이 규칙을 적용할 수 있다. 우리가 다음과 같이 변수를 선언했다고 가정해 보자.
double value = 31.0;
int coutn = 16;
float many = 2.0f;
char num = 4;
또한, 다음과 같이 다소 임의의 산술 문장을 가지고 있다고 생각해 보자.
value = (value - count) * (count - num) / many + num / many;이제, 우리는 컴파일러가 어떤 변환 작업을 할 것인지 생각해 볼 수 있다. 첫 번째 작업은 (value - count)를 계산하는 것이다. 1번 규칙은 적용되지 않고, 2번 규칙이 적용된다. 그러므로 count의 값은 double로 변환되고, 그 double의 결괏값은 15.0이 된다. 다음으로, (count - num)이 계산되어야 한다. 그리고 여기서 첫 번째로 작용되는 순서에 관한 규칙은 4번째 규칙이다. 그러므로 num은 char로부터 int로 변환되고, 그 결과인 12는 int 형식의 값으로서 계산된다. 다음의 계산은 처음의 두 결과인 double 15.0과 int 12를 서로 곱하는 것이다. 여기서는 2번 규칙이 적용되어서 12가 double로서 12.0으로 변환된다. 그리고 결과인 18.0이 double로서 계산된다. 이제, 그 결과는 many에 의해서 나누어져야 한다. 그러므로 2번 규칙이 다시 적용되어서 double로 90.0이라는 결과가 계산되기 전에 many의 값이 double로 변환되다. num / many라는 표현이 그다음으로 계산된다. 여기서는 3번 규칙이 적용되어서 num의 형식을 char에서 float로 변환한 후에 float 형식의 2.0f라는 결과가 계산된다. 마지막으로, double 형식의 90.0이 float 형식의 2.0f에게 더하여지는데, 이때 2번 규칙이 적용된다. 그러므로 float 형식의 2.0f를 double 형식의 2.0으로 변환시킨 다음, 마지막 결과인 92.0이 value 안에 저장된다.
위의 설명이 마치 경매 상의 말처럼 들리지만, 여러분이 일반적인 규칙을 이해하기 바란다.
할당 문에서의 변환 작업
우리가 이 장의 초반부에 있는 예에서 살펴보았듯이 여러분은 등호의 왼쪽에 있는 변수의 형식과는 다른 형식을 가지고 있는 할당 문의 오른쪽에 표현을 작성함으로써 함축적인 변환을 할 수 있다. 이것은 변수의 값이 변경되고, 정보를 잃어버릴 위험이 있다. 예를 들어, 여러분이 float 또는 double을 int 또는 long 변수에게 할당했으면 float 또는 double의 소수점 이하 부분은 잃게 될 것이고, 단지 정수 부분만이 저장될 것이다(만약 여러분의 부동 소수점 변수가 그것과 연관된 정수 형식이 사용할 수 있는 범위를 초과한다면 더 많은 정보를 잃어버릴 염려가 있다).
예를 들어, 다음의 코드가 실행된 다음에
int number = 0;
float decimal = 2.5f;
number = decimal;
number 변수의 값은 2가 될 것이다. 이때 2.5라는 상수 끝에 있는 f를 보라. 이것은 컴파일러에게 이 상수가 단이 정도의 정확성을 가지는 부동 소수점이라는 것을 나타낸다. f를 사용하지 않으면 디폴트는 double이 될 것이다. 소수점을 포함하는 모든 상수는 부동 소수점이다. 만약 여러분이 그것이 double의 정확도를 가지는 것을 원하지 않는다면 f를 붙여야 한다. 대문자 F도 f와 동일하다.
명시적인 변환
기본적인 형식과 혼합된 표현에서 여러분의 컴파일러는 자동적으로 필요한 변환 작업을 한다. 그러나 여러분은 명시적인 변환 작업을 통하여 하나의 형식을 다른 형식으로 강제로 변환시킬 수 있다. 표현의 어떤 값을 주어진 형식으로 변환시키려면 여러분은 다음과 같은 형식으로 변환 문을 작성할 수 있다.
static_cast<the_type_to_convert_to>(expression)
static_cast라는 키워드는 변환 작업이 정적으로 검사 된다는 것을 반영한다. 즉, 여러분의 프로그램이 컴파일될 때 검사 된다. 변환된 값을 사용하는 것이 안전한 지를 보기 위해서 여러분이 프로그램을 실행시킬 때 어떠한 검사도 하지 않는다. 나중에 우리가 클래스에 대해서 다룰 때 dynamic_cast라는 것을 보게 되는데, 여기서의 변환 작업은 동적(즉, 프로그램이 실행될 때)으로 이루어진다. 또한, 다른 종류의 두 가지 변환이 있는데, const_cast는 표현 안에 있는 const형식을 제거한다. 그리고 reinterpret_cast는 무조건적인 변환이다. 그러나 우리는 여기서 이러한 변환들에 대해서 더 이상 얘기하지 않을 것이다.
static_cast는 expression으로부터 계산된 결괏값을 여러분이 꺽쇠 안에서 지정한 형식으로 변환한다. expression은 하나의 변수에서부터 많은 수의 중첩된 괄호를 포함하고 있는 복잡한 표현에 이르기까지 그 어떠한 것도 될 수 있다.
다음은 static_cast <>()를 사용한 예이다.
double value1 = 10.5;
double value2 = 15.5;
int whole_number = static_cast<int>(value1) + static_cast<int>(value2);whole_number 변수의 초기값은 value1과 value2의 정수 부분의 합이다. 그러므로 그것들은 명시적으로 int 형식으로 변환된다. 그러므로 whole_number 변수는 초기값으로 25를 가지게 된다. 변환 작업은 value1과 value2 안에 저장되어 있는 값에는 영향을 미치지 않아서 각각 10.5와 15.5로 그대로 남아 있는다. 변환 작업에 의해서 생성되는 10과 15라는 계산 작업에 사용되기 위해서 단지 임시적으로만 저장되었다가 폐기된다. 비록 두 가지 변환에 의해서 계산 과정에 정보를 잃게 되지만, 컴파일러는 항상 여러분이 명시적으로 변환 작업을 지정할 때는 여러분이 무엇을 하고 있는지를 여러분이 알고 있다고 가정한다.
또한, 서로 다른 형식을 가진 값을 할당하는 것에 관련하여 우리가 앞의 예에서 설명했던 것처럼 명시적으로 변환 작업을 함으로써 여러분이 변환 작업을 필요로 한다는 사실을 항상 명확하게 밝힐 수 있다.
strips_per_roll = static_cast<int>(rolllength / height);
여러분은 명시적인 변환 작업을 모든 표준 형식에 대해서 사용할 수 있다. 그러나 여러분은 정보를 잃어버릴 염려가 있다는데 조심해야 한다. 만약 여러분이 float 또는 double값을 long으로 변환시켰다면, 여러분은 변환된 값의 소수점 이하 부분을 잃게 된다. 그러므로 그 값이 1.0보다 작은 값으로 시작되었다면 그 결과는 0이 될 것이다. 만약 여러분이 double을 float로 변환시켰다면 그 값의 정확도가 떨어지게 될 것이다. 왜냐하면, float 변수는 단지 7자리의 정확도만을 가지는 반면, double 변수는 15자리를 갖는다. 심지어 정수 형식 사이에서의 변환 작업도 변환되는 값에 따라서는 데이터를 잃어버릴 염려가 있다. 예를 들어, long 형식을 가지는 정수는 여러분이 short 형식의 변수 안에 저장할 수 있는 값의 범위를 초과할 수 있다. 그러므로 long값에서 short로의 변환은 정보를 잃어버릴 위험이 있다.
일반적으로, 여러분은 가능하면 변환을 하지 말아야 한다. 만약 여러분이 프로그램에서 많은 변환 작업을 해야 한다면 여러분 프로그램의 전체적인 설계는 복잡하게 될 것이다. 여러분은 프로그램의 구조와 여러분이 데이터 형식을 선정한 방식을 살펴보아서 프로그램에서 변환 작업을 하지 않거나, 적어도 그 횟수를 줄이는 방법을 찾아야 할 것이다.
오래된 방식의 변환 작업
static_cast<>()(그리고 우리가 나중에 살펴볼 const_cast <>(), dynamic_cast <>(), 그리고 reinterpret_cast <>()와 같은 다른 종류의 변환)가 C++에서 사용되기 전에 표현의 결괏값을 다른 형식으로 명시적으로 변환하는 문장을 다음과 같이 썼다.
(the_type_to_convert_to)expressionexpression의 결과는 괄호 안에 있는 형식으로 변환된다. 예를 들어, 이전의 샘플에서 strips_per_roll을 계산하는 문장을 다음과 같이 쓸 수 있다.
strips_per_roll = (int)(rolllength / height);본질적으로, 4종류의 변환 작업이 있는데, 이전 방식의 변환 문법이 그것들 모두를 포함한다. 이러한 이유 때문에 이전 방식의 변환을 사용하는 코드가 더 에러를 많이 발생시키는 경향이 있다. 즉, 그러한 방식은 항상 여러분의 의도를 명확하게 전달하지 못한다. 그리고 여러분은 예상치 못한 결과를 얻게 될 수도 있다. 여러분이 이전 방식의 변환이 폭넓게 사용되는 것을 보게 되겠지만(그것은 여전히 언어에 포함되어 있다), 필자는 여러분이 코드에서 새로운 방식의 변환만을 사용할 것을 강력하게 권하는 바이다.
5.1 bitwise 연산자
bitwise 연산자는 그것의 피연산자를 수치값이 아닌 일련의 개별적인 비트로서 다룬다. 이 연산자는 단지 정수 변수 또는 상수만을 피 연산자로 사용한다. 그러므로 short, int, long, 그리고 char 데이터 형식만이 사용될 수 있다. 이러한 연산자는 하드웨어 장치에 대한 프로그래밍을 할 때 유용하다. 그러한 경우, 하드웨어 장치의 상태가 종종 일련의 개별적인 플래그(즉, 바이트의 각 비트는 그 장치의 다른 측면의 상태를 나타낸다)로서 표현된다. 또는, 여러분이 on/off 상태를 나타내는 플래그의 set을 하나의 변수 안에 포함시키고자 할 때 이 연산자가 유용하댜 우리가 입 • 출력을 자세하게 다룰 때에 여러분은 이러한 연산자를 보게 될 것이다. 그 경우, 하나의 비트는 데이터가 처리되는 다양한 옵션을 제어하는 데 사용된다.
6가지 의 bitwise 연산자가 있다.

각각의 연산자가 어떻게 작동하는지에 대해서 살펴본다.
bitwise AND
bitwise AND(즉, &)는 작업의 대상이 되는 비트를 그것의 피연산자와 결합시키는 이진 연산자이다. 만약 그 두 개의 비트가 모두 1이라면 결과는 1 이 된다. 만약 그 두 개가 모두 0 이거나 어느 하나가 0이라면 결과는 0 이 된다.
특별한 이진 연산자의 결과는 종종 진리표라는 것을 사용하여 나타낸다. 이 표는 피연산자의 다양한 조합에 대해서 그 결과가 어떤 것인지를 나타낸다. &에 대한 진리표는 다음과 같다.

각 행과 열의 조합에서 그 두 개의 피연산자를 결합시키는 &의 결과는 행과 열이 만나는 곳에 위치한다. 이것이 어떻게 작동하는지 샘플을 통하여 살펴본다.
char letter1 = 'A', letter2 = 'Z', result = 0;
result = letter1 & letter2;
어떤 작업이 발생하는지를 살펴보려면 비트' 패턴에 대해서 알아야 한다. 'A'와 'Z' 문자는 16 진수 값으로, 각각 0x41과 0x5A에 해당된다. bitwise AND가 이러한 두 가지 값에 대해서 작동하는 방식이 아래에 나타나 있다.
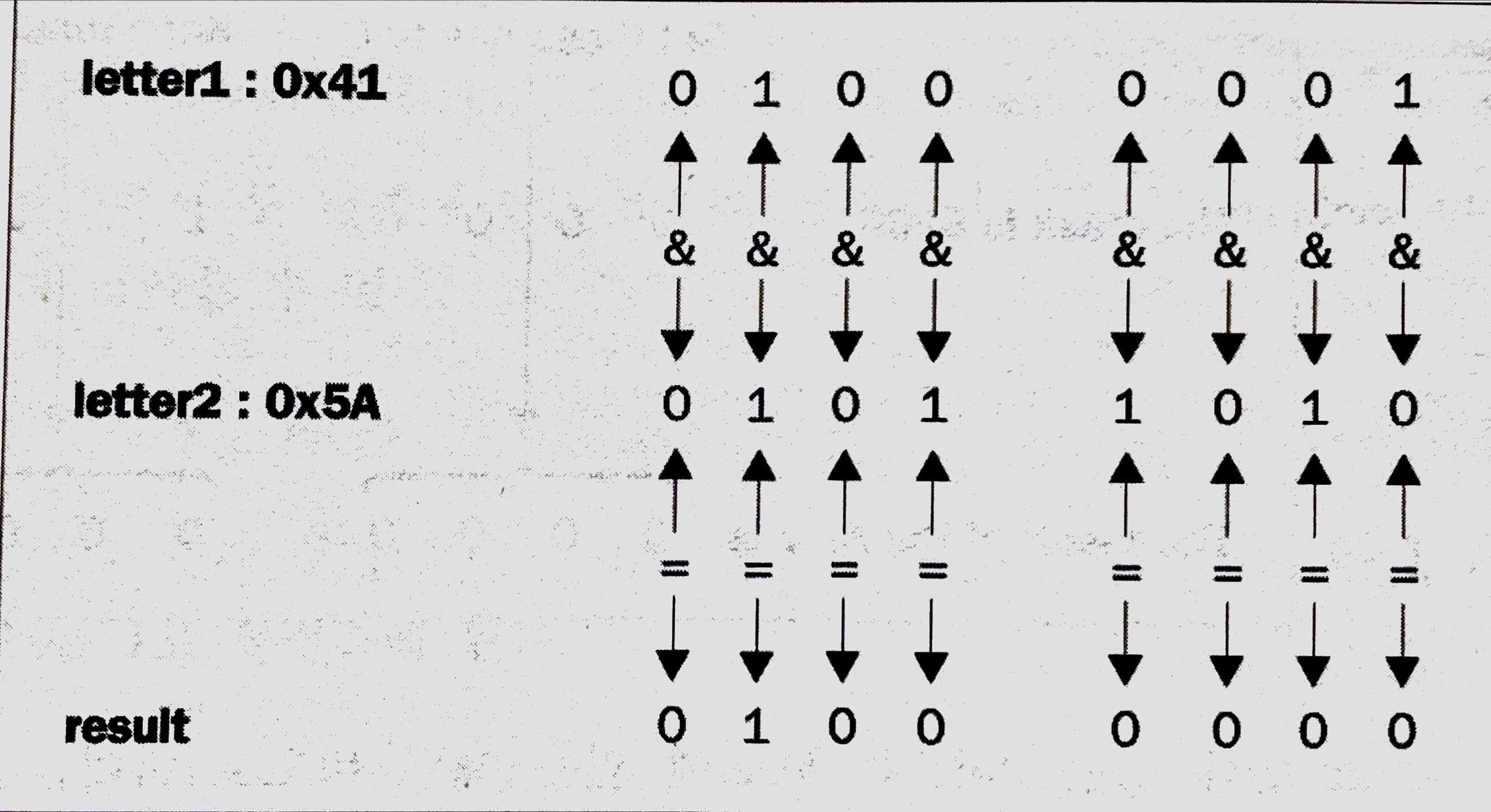
여러분은 해당되는 비트가 &와 함께 어떻게 진리표 안에서 결합되는지를 살펴봄으로써 그것의 작동 방식을 알 수 있다. 할당문 뒤에 result는 0x40 값을 가지는데, 그것은 '@' 문자에 해당한다.
만약 두 개의 비트가 0이라면 &는 0을 생성하기 때문에, 우리는 이 연산자를 사용하여 변수 안에 있는 불필요한 비트를 0으로 만들 수 있다. 그렇게 하려면 ‘마스크 (mask)'라는 것을 생성한 다음, & 연산자를 사용하여 그것을 원래의 변수와 결합시키면 된다. 우리는 비트를 보존하고자 하는 곳에는 1을 놓고, 0으로 만들고자 하는 곳에는 0을 놓음으로써 마스크를 생성한다. 마스크의 비트가 0 인 곳에서는 결과가 0이 된다. 그리고 마스트가 1 인 곳에서는 변수 안에 있는 원래의 비트와 동일한 값을 가진다. 예를 들어, 우리가 char 형식을 가지는 letter 변수를 가지고 있다고 생각해 보자. 우리는 상위에 있는 4개의 비트를 지우고, 하위에 있는 4개의 비트는 유지하려고 한다. 그렇게 하려면 다움과 같이 마스크를 0x0F로 설정하고, &를 사용하여 그것을 letter와 결합시키면 된다.
letter = letter & 0x0F;
또는 좀 더 정확하게,
letter &= 0x0F;만약 letter가 0x41로 시작되었다면 그것은 위의 두 문장의 결과로 0x01 로서 끝나게 될 것이다. 이 작업의 과정이 아래에 나타나 있다.

마스크 안에 있는 0비트는 letter에 있는 해당 비트로 하여 금 0으로 설정되게 한다 그리 고 마스크에 있는 1 비트는 해당되는 비트 값을 보존한다.
그와 비슷하게 여러분은 상위의 4개 비트를 보존하고, 하위의 4개 비트를 0으로 설정하기 위해서 0xF0 마스크를 사용할 수 있다. 그러므로 문장은 다음과 같이 된다.
letter &= 0xF0;
위의 결과는 letter의 값이 0x41에서 0x40으로 바뀌게 한다.
bitwise OR
bitwise OR(I)는 때로 inclusive OR라고 불리는데, 작업의 대상이 되는 비트를 결합시킨다. 이때 두 개의 피연산자 비트 중 하나가 1이라면 결과는 1 이 되고, 두 개 모두 0이라면 결과는 0 이 된다. bitwise OR에 대한 진리표는 다음과 같다.

우리가 개별적인 플래그들을 어떻게 int 형식을 가지는 하나의 변수 안에 놓을 수 있는지를 샘플을 통해서 알아볼 수 있다. 우리가 short 형식을 가지는 style이라는 변수(16개의 개별적인 1 비트 플래그를 포함한다)를 가지고 있는데, 우리가 그 style 변수 안에 있는 개별적인 플래그들을 설정하는 데 관심을 가지고 있다고 생각해 보자. 그렇게 할 수 있는 한 · 가지 방법은 특정한 비트를 on 시킬 수 있는 값을 정의해서 OR 연산자를 사용하여 그 값과 결합시키는 것이다. 가장 오른쪽에 있는 비트를 설정하는 데 사용하기 위해서 우리는 다음과 같이 정의한다.
short vredraw = 0x01;맨 오른쪽에서 두 번째에 있는 비트를 설정하려고 우리는 hredraw 변수를 다음과 같이 정의할 수 있다.
short hredraw = 0x02;그러므로 다움과 같이 우리는 style 변수 안에 있는 가장 오른쪽에 있는 두 개의 비트를 1로 설정하게 된다.
short = hredraw | vredraw;
위 문장의 결과가 다음의 그림에 나타나 있다.

OR 연산은 두 개의 비트 중 어느 하나가 l 이면 결과가 l 이기 때문에 두 변수를 OR 연산시키면 두 개의 비트가 모두 on 된다.
매우 일반적인 작업을 통해서도 다른 곳에 설정되어 있는 값을 변경시키지 않고서도 변수 안에 있는 플래그들을 설정할 수 있다. 우리는 다음과 같은 문장을 통해서 그러한 작업을 매우 쉽게 할 수 있다.
style |= hredraw | vredraw;위의 문장은 style 변수의 가장 오른쪽 두 개의 비트를 1로 설정하고, 다른 비트들을 이 문장이 실행되기 이전의 상태로 유지한다.
bitwise exclusive OR
exclusive OR(^)는 두 개의 피연산자가 모두 1 일 때 결과로 0을 생성하는 것만을 제외하고는 그것이 inclusive OR와 비슷하게 작동하는 데서 이러한 이름으로 불린다. 그러므로 진리표는 다음과 같이 된다.

우리가 AND에서 사용했던 동일한 변수값을 사용하여 우리는 다움의 문장에 대한 결과를 볼 수 있다.
result = letter1 ^ letter2;이 작업을 다음과 같이 표현할 수 있다.
letter1 0100 0001
letter2 0101 1010
위의 두 개를 OR 연산시키면
result 0001 1011result 변수는 0x1B 또는 십진 표수로 27로 설정된다.
^ 연산자는 약간 놀라운 특성을 가지고 있다. 우리가 이진값으로 0100 0001에 해당하는 'A'라는 값을 가지고 있는 first 변수와 이진값으로 0101 1010에 해당되는 'Z'라는 값을 가지고 있는 last 변수, 이 두 개의 char 형식의 변수를 가지고 있다고 생각해 보자. 만약 우리가 다음과 같은 문장을 쓰면
first ^= last;
last ^= first;
first ^= last;위 문장의 결과는 first와 last가 중간에서 매개하는 어떠한 메모리를 사용하지 않고서도 값을 서로 교환하게 될 것이다. 이러한 방법은 모돈 정수값에 대하여 사용할 수 있다.
bitwise NOT
bitwise NOT(~)은 피연산자 한 개의 비트를 변환한다. 즉, 1은 0 이 되고, 0은 1 이 된다 그러므로 다음의 문장을 실행시키면
result = ~letter1;
letter1의 0100 0001 값이 result 결과값에서는 1011 1110(0xBE 또는 십진수로는 190) 이 된다.
bitwise Shift 연산자
이러한 연산자들은 정수 변수의 값을 지정된 개수의 비트만큼 왼쪽으로 또는 오른쪽으로 밀어낸다. >> 연산자는 오른쪽으로 밀어내는 반면, << 연산자는 왼쪽으로 밀어낸다. 변수의 양 끝쪽에 있다가 밖으로 밀려나는 비트는 소실된다. 아래의 그림은 2바이트의 변수를 왼쪽과 오른쪽으로 밀어내는 과정을 나타내고 있다. 그리고 그 초기값도 함께 나타내었다.
우리는 다음의 문장에서 number라는 변수를 선언하고 초기화한다.
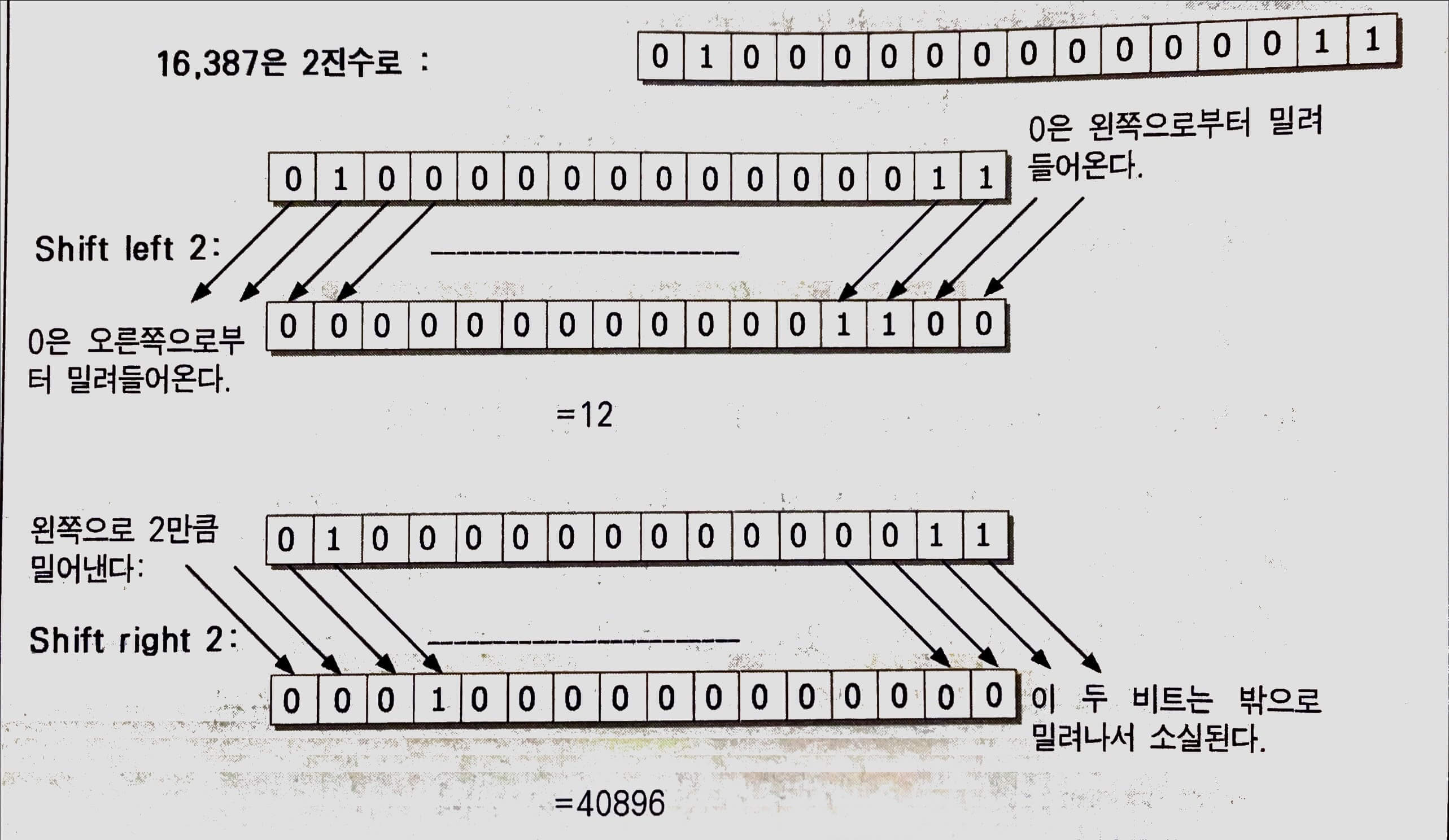
unsigned int number = 16387U;
우리가 이 장의 처음 부분에서 본 것처럼 부호를 가지지 않는 정수 리터럴을 쓸 때는 그 앞에 U 또는 u를 붙여야 한다. 우리는 다음의 문장을 통하여 이 변수의 값을 밀어낼 수 있다.
number <<= 2; // 왼쪽으로 2비트 밀어낸다.
shift 연산자의 왼쪽에 있는 피연산자는 밀려지는 값이다. 그리고 값이 밀려나갈 비트의 개수는 오른쪽에 있는 피연산자에 의해서 지정된다. 위의 그림은 왼쪽 작업의 결과를 나타내고 있다. 여러분도 볼 수 있듯이 16,387이라는 값을 왼쪽으로 두 자리 밀어내면 12가 된다. 그 값에 있어서의 약간 극적인 변화는 상위에 있는 비트를 잃는다는 것이다.
또한, 우리는 그 값을 오른쪽으로 밀 수 있다. number의 값을 그것의 초기값인 16,387로 설정하자. 그런 다음, 우리는 다음과 같이 쓸 수 있다.
number >>=2; // 오른쪽으로 2비트 밀어낸다.
위의 문장은 16,387 값을 두 자리 오른쪽으로 밀어내서 그 결과값인 4,096을 저장한다. 두 비트 오른쪽으로 밀어내면 그 값을 4로 나누는 결과가 된다(나머지 값이 없이). 이것도 그림에 나타나 있다.
비트가 소실되지 않는 한 n비트만큼을 왼쪽으로 밀면 그 값을 2로 n번 곱한 결과가 된다. 다시 말해서, 그 값에 2n승을 곱한 것과 같다. 그와 비슷하게 n 비트만큼 오른쪽으로 밀면 그 값을 2n승으로 나눈 것과 같다. 여기서 조심해야 할 것은 우리가 number 변수를 왼쪽으로 밀 때 본 것처럼 중요한 비트가 소실되면 그 결과는 여러분이 기대하는 것과는 전혀 다른 것이 된다는 것이다. 그러나 이것은 곱셈 작업과 전혀 다르지 않다. 만약 여러분이 2바이트의 숫자에 4를 곱하면 동일한 결과를 얻게 될 것이다. 그러므로 왼쪽으로 미는 것과 곱하는 것은, 여전히 동일한 결과를 낸다. 이때 정확도에 관한 문제가 발생하는데, 그것은 곱셈 작업의 결과값이 2바이트 정수의 범위를 넘는다는 것이다.
여러분은 지금까지 입 · 출력 작업에서 사용해 온 연산자와 혼동되지 않을까라고 생각할 수도 있다. 그러나 컴파일러는 그 의미를 항상 전후 문맥을 통해서 명확하게 파악할 수 있다. 만약 그렇지 않으면 컴파일러는 메시지를 발생시킨다. 그러나 여러분은 이러한 작업을 할 때 조심해야 한다. 예를 들어, 여러분이 number 변수를 왼쪽으로 2비트만큼 밀어냈을 때의 결과를 출력하고자 한다면 여러분은 다음과 같이 작성할 수 있다.
cout << (number << 2);
여기서 괄호가 반드시 필요하다. 괄호가 없으면 shift 연산자는 컴파일러에 의해서 스트림 연산자로 인식된다. 그러므로 여러분은 의도하지 않은 결과를 얻게 될 것이다.
대체로, 오른쪽으로 밀어내는 작업은 왼쪽으로 밀어내는 작업과 비슷하다. 예를 들어, number 변수가 24라는 값을 가지고 있는 상태에서 다음의 문장을 실행시킨다면
number >= 2;
number가 6이라는 값을 가지는데, 이것은 그 값을 4로 나눈 결과이다. 그러나 음의 값(즉, 가장 왼쪽에 있는 비트로서 그것은 부호를 나타내는 비트인데, 1의 값을 가진다)을 가지는 signed 정수 형식의 경우, 오른쪽으로 밀어내는 과정은 특별한 방식으로 진행된다. 이 경우, 부호를 나타내는 비트는 오른쪽으로 전달된다. 예를 들어, char 형식을 가지는 number 변수를 선언하고, 그것을 십진수로 -104 값을 가지는 것으로 초기화하자.
char number -= 104; // 이진 표현은 1001 1000이다.이제, 다음가 같이 우리는 그것을 1비트만큼 오른쪽으로 밀 수 있다.
number >>=2; // 결과 : 1110 0110부호를 나타내는 비트는 보존되므로 결과의 십진수 값은 -26이다. 물론, unsigned 정수 형식에 대한 작업에서는 부호를 나타내는 비트가 보존되지 않고, 0이 나타난다.
* 어떤 컴퓨터에서는 이러한 밀어내기 작업은 보통의 곱셈 또는 나눗셈 작업보다 빠르다. 예를 들어, 인텔 x86에서는 곱셈 작업이 왼쪽으로 밀어내는 것보다 적어도 3배나 느리다. 그러나 여러분이 필요로 하는 비트를 잃지 않으려면 보통의 방법을 사용해야 한다.
'코딩 > C와 C++' 카테고리의 다른 글
| [C++ 기초 강좌] 7. 네임 공간(namespace) (0) | 2021.05.17 |
|---|---|
| [C++ 기초 강좌] 6. 범위에 대한 이해 (0) | 2021.05.15 |
| [C++ 기초 강좌] 4. C++ 계산 작업 (0) | 2021.03.13 |
| [C++ 기초 강좌] 3. C++ 데이터 형식 (0) | 2021.03.11 |
| [C++ 기초 강좌] 2. C++ 변수 정의하기 (0) | 2021.03.11 |